值函数近似
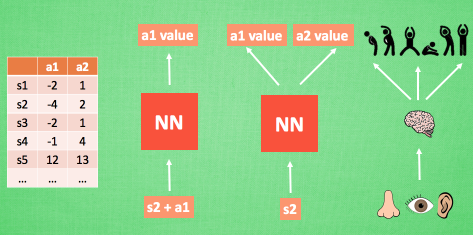
表格型方法是使用表格来存储每一个状态 state,和在这个 state 每个行为 action 所拥有的 Q 值。而当今问题实在太复杂,状态可以多到比天上的星星还多(比如下围棋)。如果全用表格来存储它们,恐怕我们的计算机有再大的内存都不够,而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事。
不过,在机器学习中,有一种方法对这种事情很在行,那就是神经网络。我们可以将状态和动作当成神经网络的输入,然后经过神经网络分析后得到动作的 Q 值,这样我们就没必要在表格中记录 Q 值,而是直接使用神经网络生成 Q 值。还有一种形式的是这样,我们也能只输入状态值,输出所有的动作值,然后按照 Q learning 的原则,直接选择拥有最大值的动作当做下一步要做的动作。我们可以想象,神经网络接受外部的信息,相当于眼睛鼻子耳朵收集信息,然后通过大脑加工输出每种动作的值,最后通过强化学习的方式选择动作。
更新神经网络
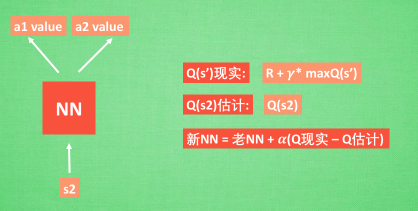
接下来我们基于第二种神经网络来分析,我们知道,神经网络是要被训练才能预测出准确的值。那在强化学习中,神经网络是如何被训练的呢? 首先,我们需要 a1,a2 正确的Q值,这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替。同样我们还需要一个 Q 估计 来实现神经网络的更新。所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距。我们整理一下。
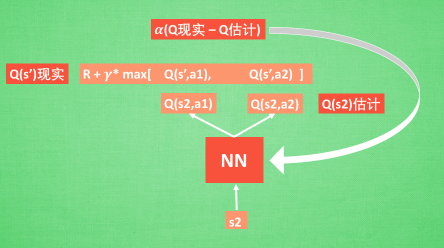
我们通过 NN 预测出和的值, 这就是 Q 估计。然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward。而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s’ 的估计。最后再通过刚刚所说的算法更新神经网络中的参数。但是这并不是 DQN 会玩电动的根本原因。还有两大因素支撑着 DQN 使得它变得无比强大。这两大因素就是 目标网络 和 经验回放。
目标网络
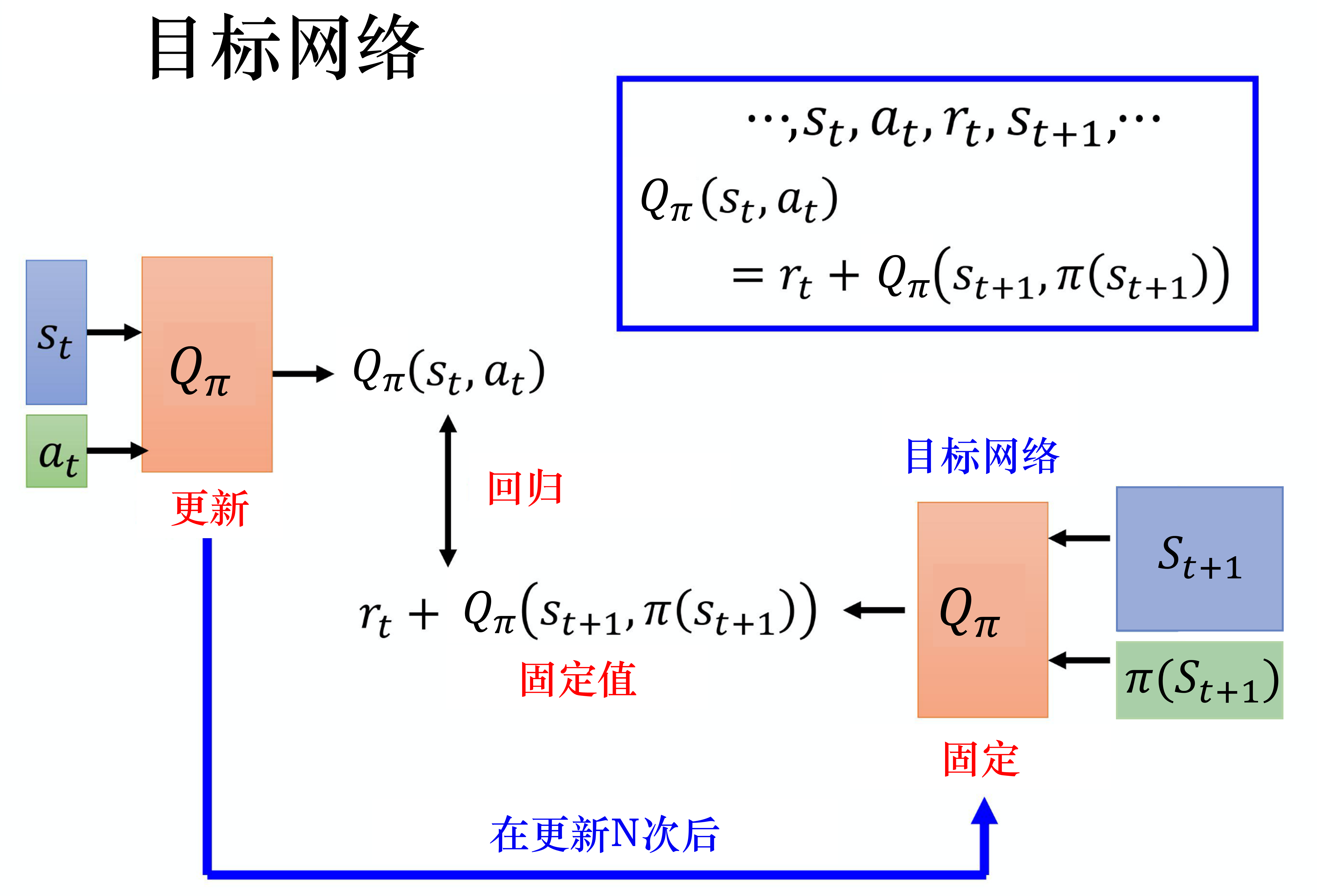
上述分析可知,Q 现实和 Q 估计是同一个网络,这样 Q 现实是同步变动的,这样会导致训练不稳定,因为我们要拟合的目标一直在变,通常我们会把其中一个 Q 网络固定住(一般固定右边的目标网络),在左边的网络更新多次以后,将参数替换掉目标网络。
经验回放
经验回放会构建一个回放缓冲区(replay buffer),回放缓冲区又被称为回放内存(replay memory)。
回放缓冲区是指现在有某一个策略与环境交互,它会去收集数据,我们把所有的数据放到一个数据缓冲区(buffer)里面,数据缓冲区里面存储了很多数据。比如数据缓冲区可以存储 5 万笔数据,每一笔数据就是记得说,我们之前在某一个状态,采取某一个动作,得到了奖励,进入状态。我们用去与环境交互多次,把收集到的数据放到回放缓冲区里面。回放缓冲区里面的经验可能来自不同的策略,我们每次用与环境交互的时候,可能只交互 10000 次,接下来我们就更新了。但是回放缓冲区里面可以放 5 万笔数据,所以 5 万笔数据可能来自不同的策略。回放缓冲区只有在它装满的时候,才会把旧的数据丢掉。所以回放缓冲区里面其实装了很多不同的策略的经验。
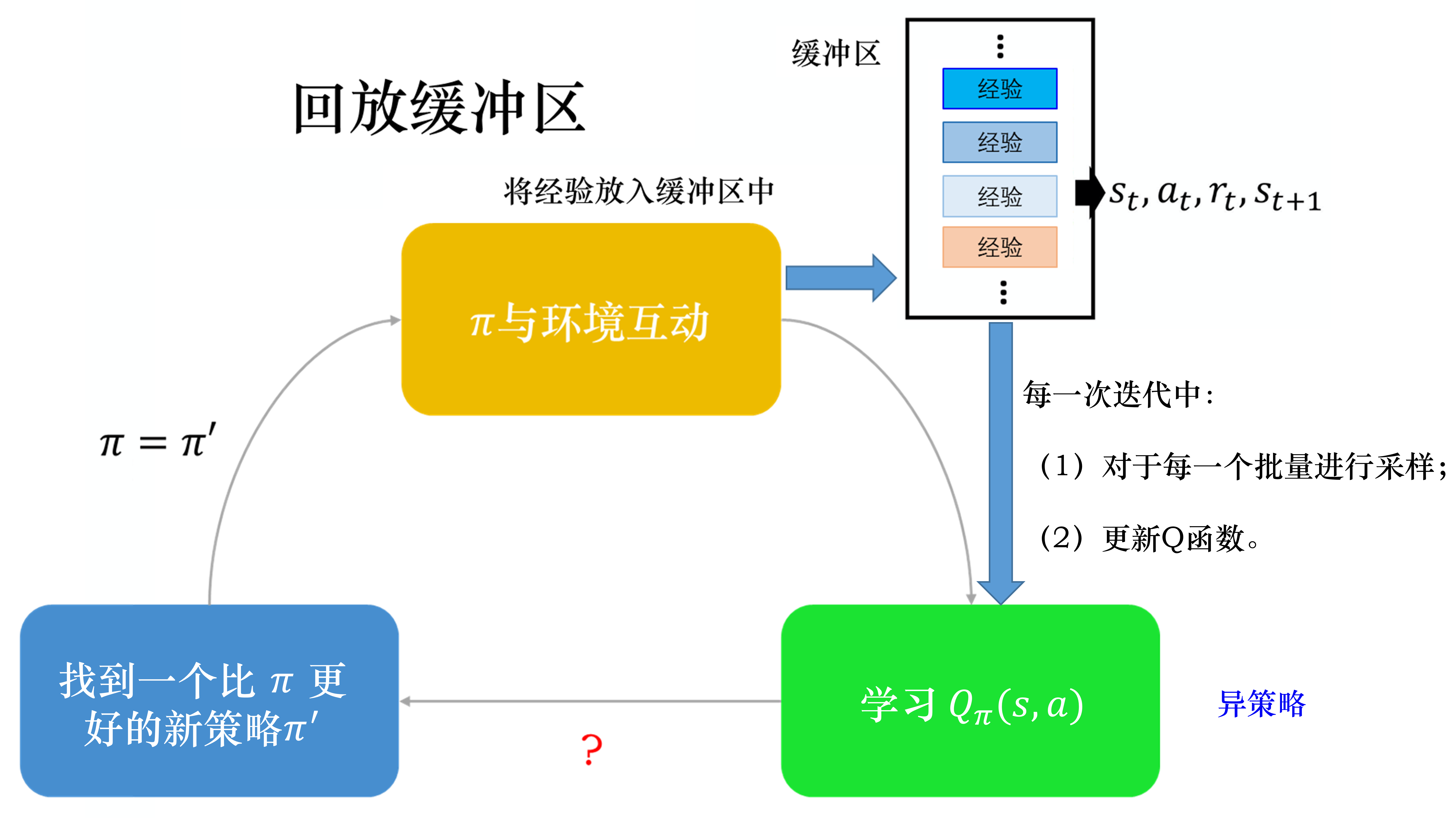
如果某个算法使用了经验回放这个技巧,该算法就变成了一个异策略的算法。
深度Q网络算法:

代码实战
Q 网络
Q 网络使用三层感知机模型,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class QNet(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=128):
super().__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.fc1 = nn.Linear(self.state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, self.action_dim)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
return x
|
经验池
经验池主要有三种操作,向经验池中放入经验、采样及清空经验池:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.memory = deque(maxlen=self.capacity)
def store(self, state, action, reward, next_state, done):
'''
向经验池中放入经验
:param state:
:param action:
:param reward:
:param next_state:
:param done:
:return:
'''
self.memory.append((state, action, reward, next_state, done))
def sample(self, batch_size, is_sequential=False):
'''
采样
:param batch_size:
:param is_sequential: 是否按照顺序抽取batch_size数量的经验
:return:
'''
if is_sequential:
rand = np.random.randint(len(self.memory) - batch_size)
batch = [self.memory[i] for i in range(rand, rand + batch_size)]
else:
batch_idxs = np.random.choice(len(self.memory), replace=False, size=batch_size)
batch = [self.memory[i] for i in batch_idxs]
return zip(*batch)
def clear(self):
'''
清空经验池
:return:
'''
self.memory.clear()
|
智能体实现
智能体一共有五种操作:下一步动作采样、预测动作、学习、训练以及测试。
下一步动作采样用于训练过程,采用-贪婪策略:
1
2
3
4
5
6
7
8
| @torch.no_grad()
def get_action(self, state):
if np.random.random() > self.epsilon:
q_value = self.policy_net(torch.tensor(state, device=self.device, dtype=torch.float32).unsqueeze(dim=0))
action = q_value.argmax().item()
else:
action = np.random.randint(self.action_dim)
|
预测动作用于测试,通过策略网络进行预测:
1
2
3
4
| @torch.no_grad()
def predict_action(self, state):
return self.policy_net(
torch.tensor(state, device=self.device, dtype=torch.float32).unsqueeze(dim=0)).argmax().item()
|
学习是根据更新公式更新策略网络:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def learn(self):
if self.epsilon > self.epsilon_end:
self.epsilon *= self.epsilon_decay
if len(self.memory.memory) < self.batch_size:
return
state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.memory.sample(self.batch_size)
state_batch = torch.tensor(np.array(state_batch), device=self.device, dtype=torch.float32)
action_batch = torch.tensor(action_batch, device=self.device).unsqueeze(1)
reward_batch = torch.tensor(reward_batch, device=self.device, dtype=torch.float32)
next_state_batch = torch.tensor(np.array(next_state_batch), device=self.device, dtype=torch.float32)
done_batch = torch.tensor(done_batch, device=self.device, dtype=torch.int)
q_values = self.policy_net(state_batch).gather(dim=1, index=action_batch)
next_q_values = self.target_net(next_state_batch).max(1)[0].detach()
expected_q_values = reward_batch + self.gamma * next_q_values * (1 - done_batch)
loss = nn.MSELoss()(q_values, expected_q_values.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
|
训练函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def train(self, env, args):
print('******开始训练!******')
rewards = []
for i_ep in range(args.train_eps):
ep_reward = 0
state = env.reset()
if i_ep % args.target_update == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
for _ in range(args.train_ep_max_steps):
if self.render:
env.render()
action = self.get_action(state)
next_state, reward, done, _ = env.step(action)
self.memory.store(state, action, reward, next_state, done)
state = next_state
self.learn()
ep_reward += reward
if done:
break
if i_ep % 50 == 0:
print(f"回合:{i_ep + 1}/{args.train_eps},奖励:{ep_reward:.2f},Epislon:{self.epsilon:.3f}")
rewards.append(ep_reward)
return rewards
|
测试函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def test(self, env, args):
print('******开始测试!******')
rewards = []
for i_ep in range(args.test_eps):
ep_reward = 0
state = env.reset()
for _ in range(args.test_ep_max_steps):
if self.render:
env.render()
action = self.predict_action(state)
next_state, reward, done, _ = env.step(action)
state = next_state
ep_reward += reward
if done:
break
print(f"回合:{i_ep + 1}/{args.test_eps},奖励:{ep_reward:.2f},Epislon:{self.epsilon:.3f}")
rewards.append(ep_reward)
return rewards
|
完整代码链接见:MyShare/DRL/DQN/dqn.py at master · TyroGzl/MyShare (github.com)
备用地址:关注公众号【G的科研生活】,回复【DRL】
参考链接:
第六章 DQN (基本概念) (datawhalechina.github.io)
什么是 DQN - 强化学习 Reinforcement Learning | 莫烦Python (yulizi123.github.io)
dqn_zoo/DQN/dqn.py at master · deligentfool/dqn_zoo (github.com)
本文在实现中参考了多个DQN实现代码,由于当时忘记记录,在此参考链接列出不全。